![[졸업프로젝트 2탄, CNN] ResNet50 톺아보기: 구조와 코드 분석](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fdobovu%2FbtqOMpdgUdM%2FprlyXNK8PNxs9ltkKNhgp0%2Fimg.png)
ResNet 톺아보기: 구조와 코드 분석
본 글은, 2014년에 나왔음에도 불구하고 현재까지도 대표적인 CNN 구조인 ResNet에 대해 작성한 글입니다.
ResNet은 2014년 GoogLeNet과 함께 주목을 받았지만, GoogLeNet과 다르게 ResNet은 간단한 구조를 가지고, 참신한 아이디어 덕분에 현재까지도 많은 network에서 사용되고 있습니다.
ResNet50에 대해 설명하고, 직접 코드를 작성하며, 이를 통해 직접 구현한 예시를 보겠습니다.
(해당 코드는 pytorch 기반으로 작성되었으며, Gist(코드 부분) 역시 직접 작성되었습니다.)
졸업프로젝트 Yolo 모델에 기본적으로 사용되는 CNN 모델인 ResNet을 바탕으로 작성되었습니다. 본 팀은 이 기본 CNN 구조를 바탕으로 Yolo 모델에 반영하려 합니다. (졸업 프로젝트의 CNN 부분 반영)
Motivation
ResNet이 나오기 전까지 근방의 모델들은 오로지 깊은 모델 즉, 레이어를 많이/깊이 쌓아서 성능이 높은 모델을 고르는데 치중되었습니다. ResNet의 저자는 모델이 깊어질수록 최적화에 멀어진다는 점에 주목하였습니다. 이를 _Vanishing Gradient Problem_이라 합니다.
Vanishing Gradient Problem
Vanishing Gradient Problem은 딥러닝 중 Backpropagtion시 발생되는 어려움이다.
간단히 말하면, 모델이 깊어질수록 급격히 Gradient의 영향력이 줄어드는 현상입니다.
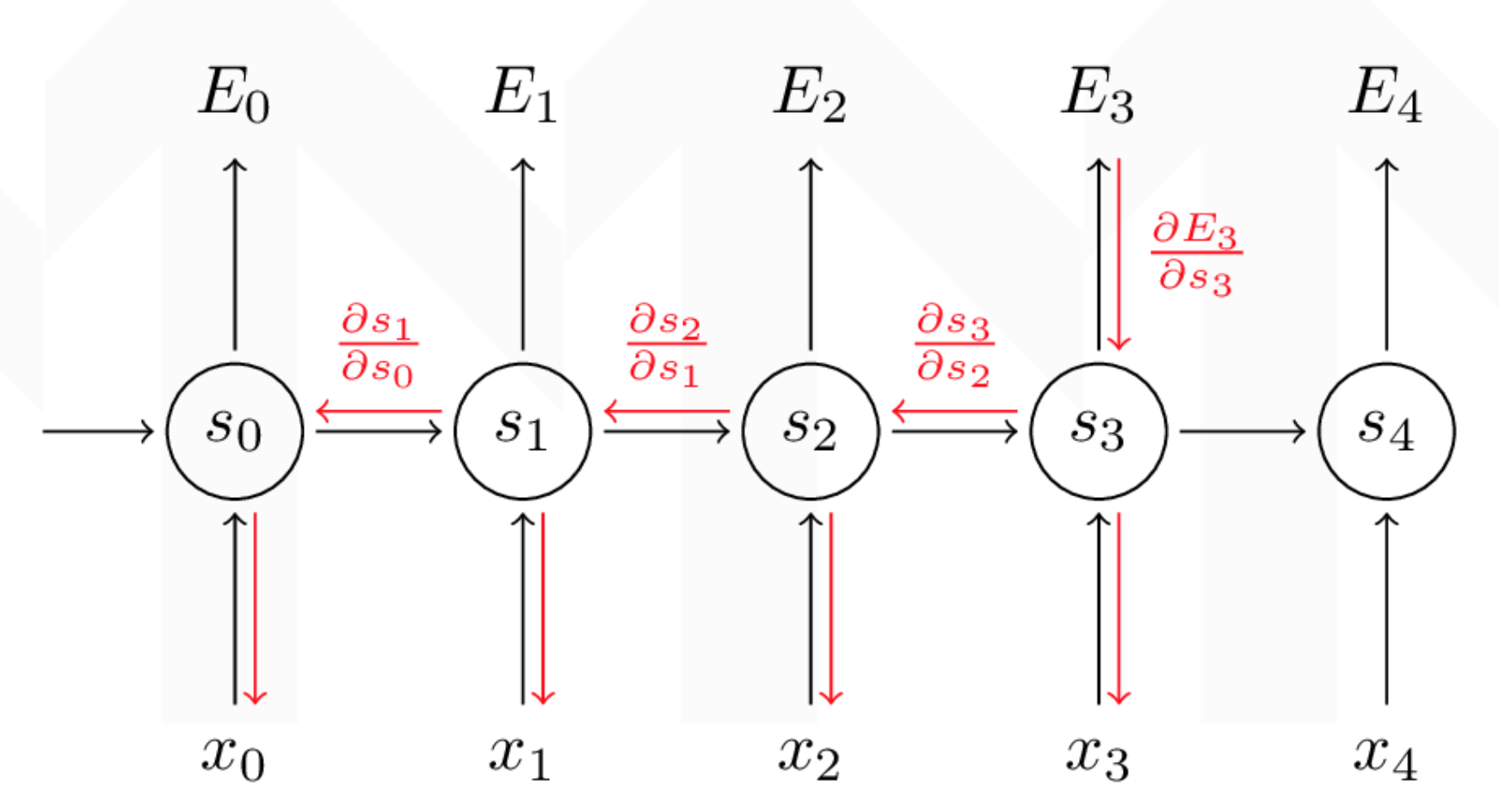
위의 그림처럼 gradient Vanishing Problem이 적용되는 것을 볼 수 있습니다.
레이어가 깊어질수록, 곱해지는 미분값들이 증가함에 따라 초기 E 값 자체에 집중하지 못하는 경향이 나타나 CNN 자체의 효능이 떨어지게 됩니다. 이에 따라 레이어를 어떻게 쌓으면 더 성능이 좋아질 지에 대해 고안을 하는 방향으로 흘렀습니다.
ResNet의 가장 기초적인 구조, Residual Block(:BottleNeck Architecture)
밑 사진은 ResNet 모델에 사용되는 가장 기본적인 구조인 Residual Block이며, 논문에서는 주로 BottleNeck Architecture로 불립니다.
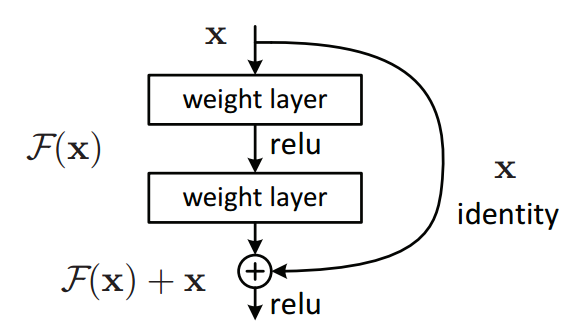
오른쪽 Block이 해당 ResNet50의 BottleNeck 구조에 해당합니다.
레이어 그림을 자세히 보면, 해당 값은 다음과 같은 input, output을 취합니다.
input: x / output : relu(F(x)+x)
이렇게 구조를 띈 layer는 _입력 값이 출력으로 그대로 더해지는 shortcut 구조_를 취하게 됩니다. 입력값이 출력값에 들어감에 따라, 레이어들이 많아지면서 입력값이 잊혀지는 vanishing gradient problem를 해결하게 됩니다.
Residual Block
위의 residual block의 내용을 바탕으로 직접 코드를 작성해보겠습니다.
이번에 구현할 ResNet50의 구조에 따라 맞는 Residual Block의 구조는 다음과 같습니다.
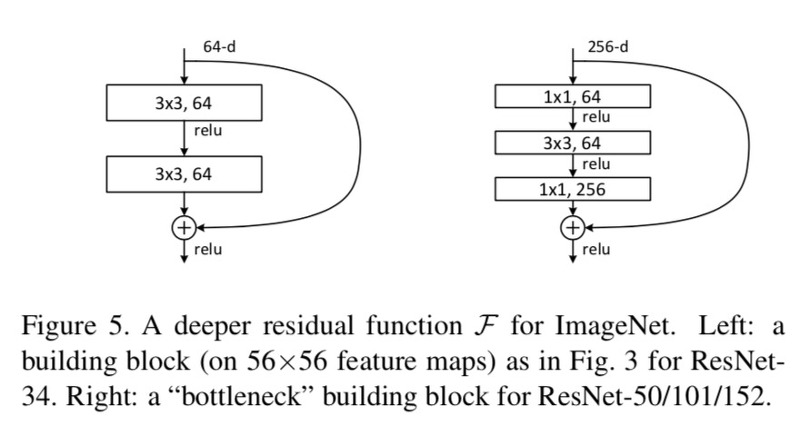
각 residual 함수 F에 관하여, 3개의 레이어 stack으로 구현하게 됩니다. 3개의 layer는 1x1, 3x3, 1x1 convolutional layer로 이루어졌습니다. 위의 그림을 보면 conv1x1 과 conv3x3을 구현해야 하므로 in_channel, out_channel을 이용해 해당 코드를 작성해보도록 하겠습니다.
1. conv1x1
위의 Figure 5의 오른쪽 모델에 기반해, 가장 첫번째 [1x1, 64]블록에 해당됩니다.
in_channel 채널 개수를 가진 데이터가 들어와 conv1x1 함수를 거치면 out_channel 채널 개수를 띄도록 구성합니다.
일반적인 convolutional layer의 형태를 띄게 작성합니다.
convolution - batch normalization - relu함수를 거치도록 작성합니다.
*Batch Normalization: Regularization의 대표적인 기법 중 하나로, batch 데이터를 바탕으로 mean과 variance를 적용해 0~1사이의 값을 가지도록 도와줍니다.
2. conv3x3
이는 Figure 5의 오른쪽 모델에 기반해, 두번째 [3x3, 64]블록에 해당됩니다.
위의 conv1x1과 동일한 흐름으로 진행됩니다. filter 크기를 1에서 3으로 바꿔줍니다. 일반적인 convolution layer와 동일하게 convolution - batch normalization - relu함수 순서를 거쳤습니다.
3. Residual Block Function 완성하기
위의 Figure 5의 오른쪽 모델에 기반해, 세번째 블록, [1x1, 256]에 해당됩니다.
다른 일반 convolution layer도 Block 함수를 거치므로 한가지 여부를 파라미터로 받아 확인해야 합니다. 이 때문에 두가지 경우로 나누어 함수를 작성하도록 합니다.즉, F(x)에 입력값 x이 합쳐져야 하는 경우이므로, input x이 F(x)와 같은 채널을 가지도록 convolution layer를 하나 더 준비해야 합니다.
Residual block이 아닌 경우, 이는 위의 추가적인 convolution layer를 준비할 필요가 없습니다.
이렇게 경우가 나뉘어지면, 실제로 구현되는 forward함수에서 downsample 파라미터 값에 따라 다른 레이어를 형성해 return 됨을 볼 수 있습니다.
전체 Layer 구분은 다음과 같습니다.
- Load Data: 데이터 로딩하기
- Train the Model: 모델 세팅 및 트레이닝 하기 <<ResNet50_layer4 사용
- Save the model checkpoint: 높은 성능 나타내는 모델 저장
- Evaluate the Model: 모델 평가하기
ResNet50 Layers
위의 residual block을 바탕으로 작성할 ResNet50 구조는 다음과 같습니다. 아래 그램의 50-layer부분에 해당합니다.
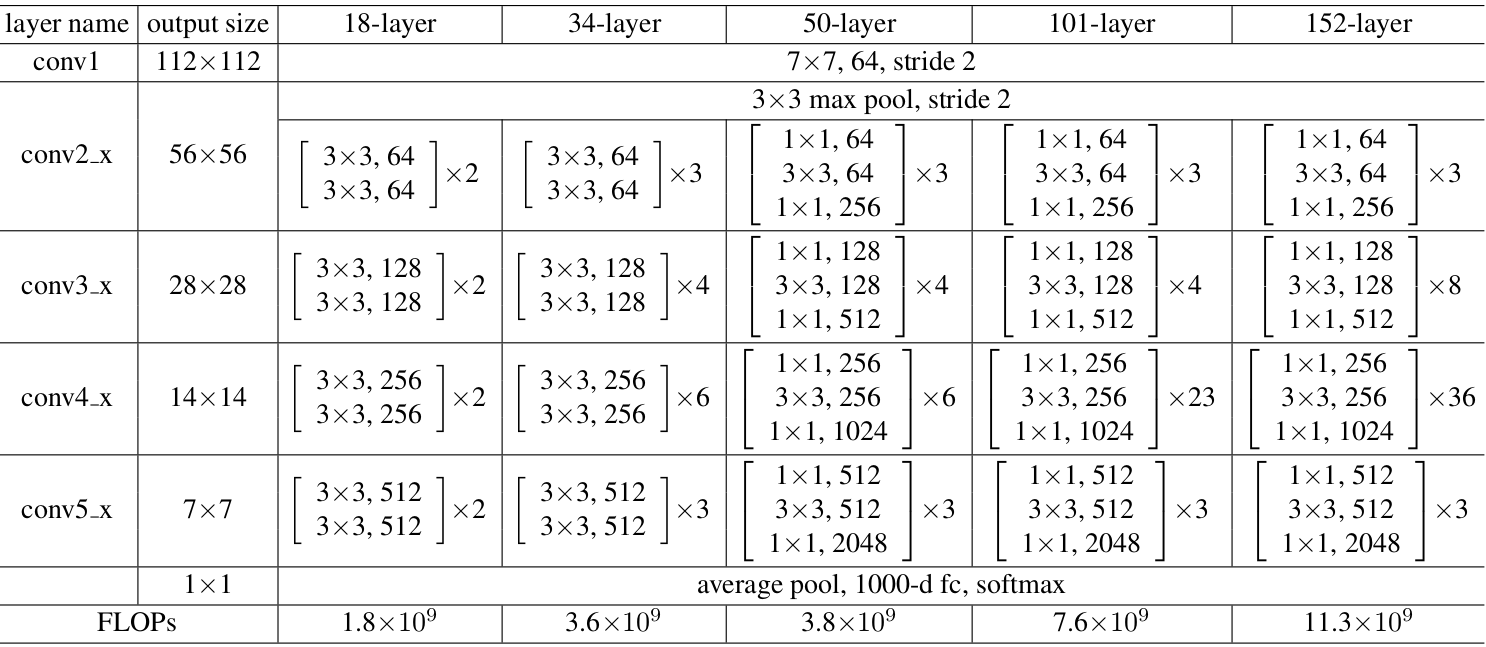
총 50개의 layer를 가지고 있으며, 각각의 conv 청크에 있는 []가 residual block 임을 명시해줍니다. 즉, resnet50은 layer마다 다른 residual block 형태가 반복되어 학습되는 과정을 거침을 알 수 있습니다.
-
Layer1
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersclass ResNet50_layer4(nn.Module): def __init__(self, num_classes= 10 ): super(ResNet50_layer4, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(3, 64, 7, 2, 3), nn.BatchNorm2d(64), nn.ReLU(inplace=True), nn.MaxPool2d(3, 2, 1) ) 7x7 convolution layer와 더불어 conv2_x 앞의 3x3 max pool까지 표현합니다.
-
Layer2
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersself.layer2 = nn.Sequential( ResidualBlock(64, 64, 256, False), ResidualBlock(256, 64, 256, False), ResidualBlock(256, 64, 256, True) ) 찬찬히 보도록 하겠습니다.
- ResidualBlock(64, 64, 256, False)
ResidualBlock(=Bottle Neck Building Block)은ReLU(1x1, 64)–ReLU(3x3, 64)–ReLu(1x1, 256)-Relu(f(x)+x)를 거쳐 나타납니다.여기서 나타나는1x1과3x3은 반복 되므로 함수로 편리하게 쓰고자 합니다.(채널 개수는64, 256로 고정된 것은 아닙니다)
이를 통해 다음과 같은 형태를 가지게 됩니다.

conv1x1, conv3x3이 반복되는 경향을 가지는 만큼 이를 쌓아서 형성하고자 합니다. Layer마다 끝에 나타나는self.downsample여부를 이용해 끝에F(x)+x처리 하는지 확인합니다.이때 가장 중요하게 적용되는 것이channel개수인데,다음 표를 보며 비교해보기로 한다. channel개수는 모든 레이어 마다 다르므로in_channels, middle_channels, out_channels로 적습니다.위의 구조에 적용하면ReLU(1x1, middle_channels)–ReLU(3x3, middle_channels)–ReLu(1x1, out_channels)로 나타낼 수 있습니다. (stride와padding정보는 생략하였다.)
-
Layer3
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersself.layer3 = nn.Sequential( ResidualBlock(256, 128, 512, False), ResidualBlock(512, 128, 512, False), ResidualBlock(512, 128, 512, False), ResidualBlock(512, 128, 512, True) ) Layer3는 Layer2와 같은 방법으로 적용하면 위와 같이 나타낼 수 있습니다.
-
Layer4: 이도 위 layer와 비슷하게 적용됩니다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersself.layer4 = nn.Sequential( ResidualBlock(512, 256, 1024, False), ResidualBlock(1024, 256, 1024, False), ResidualBlock(1024, 256, 1024, False), ResidualBlock(1024, 256, 1024, False), ResidualBlock(1024, 256, 1024, False), ResidualBlock(1024, 256, 1024, True) ) -
Layer5: 이도 위 layer와 비슷하게 적용됩니다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersself.layer5 = nn.Sequential( ResidualBlock(1024, 512, 2048, False), ResidualBlock(2048, 512, 2048, False), ResidualBlock(2048, 512, 2048, False) ) -
추가 나머지
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersself.fc = nn.Linear(2048, 10) self.avgpool = nn.AvgPool2d((2,2), stride=0) -
forward 함수
위에서 만들어준 conv 청크들을 한번에 묶어서 완전한 흐름을 만들어주겠습니다.This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersdef forward(self, x): out = self.layer1(x) out = self.layer2(out) out = self.layer3(out) out = self.layer4(out) out = self.layer5(out) out = self.avgpool(out) out = out.view(out.size()[0], -1) out = self.fc(out) return out resnet50 클래스 객체를 만들어주면, 위의 conv 청크가 만들어지고, forward 과정을 거쳐 학습됨을 알 수 있습니다.
: 이도 위 layer와 비슷하게 적용됩니다.
예제 구현하기
이번 예시에서는 CIFAR10 데이터를 10개의 클래스로 분류해보겠습니다.
위의 코드를 바탕으로 글쓴이가 모델을 구현해보았습니다. Epoch: 1, batch size: 100의 환경에서 구현하였습니다.
결과는 다음과 같았습니다.
Epoch [1/1], Step [100/500] Loss: 2.1899
Epoch [1/1], Step [200/500] Loss: 2.0328
Epoch [1/1], Step [300/500] Loss: 1.9383
Epoch [1/1], Step [400/500] Loss: 1.8728
Epoch [1/1], Step [500/500] Loss: 1.8250
Accuracy of the model on the test images: 42.3 %
Process finished with exit code 0본 내용을 해석해보면, Epoch 1번에 500 장의 train 이미지 데이터를 이용해 분류를 진행한 결과, test 데이터에서 42.3%의 성능을 보였습니다. Test 이미지 데이터에서 한 장의 사진이 10개의 클래스 중 어디에 분류되는지 정하는 task에서 100점 중 42점이 맞춰짐을 의미합니다. 이와 더불어 train이 진행함에 따라 각 batch에서 나오는 loss가 줄어듦을 보입니다.
낮의 성능의 원인은 예상하셨겠지만, Epoch을 1로 학습할 때에 성능이 확연히 떨어지고, 2 이상으로 설정시에 무려 80%까지의 정확도를 보이는 양상을 기대할 수 있겠습니다. 1번 데이터를 훑은 정도이더라도 40% 이상의 성능을 보이는 점에서 ResNet의 성능이 매우 뛰어남을 증명합니다.
Performance
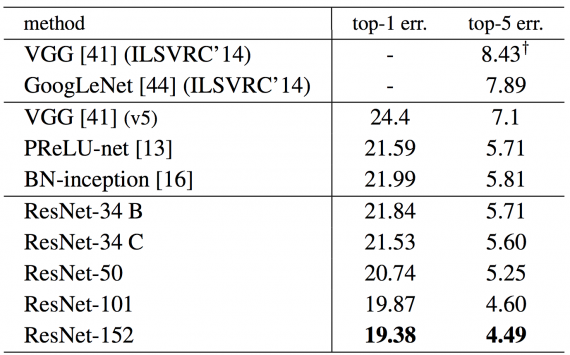

왜 detection 성적이 낮았을까?
그 때 Keras을 적용한 ResNet 적용 결과를 볼 수 있었는데, 정확도 결과는 다음과 같습니다. (https://keras.io/examples/cifar10_resnet/)
이를 보니 주 원인은 epoch에 있었던 것 같습니다. 이 코드는 epoch이 1이므 로 각각의 batch를 한번 가볍게 학습시킨 것밖에 되지 않습니다. 이에 비해 왼쪽의 표에서는 epoch가 35-200까지 돌려서 완전히 학습시키도록 하였습니다. 이를 통해 Epoch의 영향성을 볼 수 있었다. 다음에는 GPU를 꼭 사서 학습시켜봐야겠다고 느꼈습니다.
졸업프로젝트와 어떻게 연결될 수 있을까?
본 프로젝트는 Yolo 모델을 통해 이루어집니다. 밑의 Yolo 모델을 참고하면, ResNet의 Residual block이 있음을 볼 수 있습니다.
여기서 Residual layer 첨부를 통해 Input 값을 더 적용하여 향상된 성능을 보입니다. 여기서 사용되는 Yolo 기술은 다음과 같습니다.
고객을 인식하는 기술은 Computer Vision Object Detection 의 기술로 구현합니다. 자율 주행 카트의 카메라를 통해 들어온 이미지는 객체 탐지 알고리즘으로 딥러닝을 통해 사진 속에 사람 정보를 얻게 됩니다. 본 팀은 최신의 성능이 우수한 알고리즘을 논문을 통해 참조하고 프로젝트에 , 가장 적합한 알고리즘을 고르는 방법을 취하려 합니다. 알고리즘 선정 이후에 데이터 정제 및 코드 수정을 통한 customize를 통해 완전한 알고리즘을 결정합니다. 해당 알고리즘을 통해 타 업체 서비스보다 더 우수한 추종 기술을 갖추게 됩니다.
이러한 기술 연결을 통해 하나의 완전한 자율주행카트를 구현할 수 있습니다.
'Projects > Graduation Project' 카테고리의 다른 글
| [졸업프로젝트 4탄, 알고리즘 학습] AWS EC2로 딥러닝 모델 학습하기 (0) | 2021.05.15 |
|---|---|
| [졸업프로젝트 개요, 1탄 RNN] 딥러닝을 이용한 자율주행카트 (0) | 2020.11.19 |
| [졸업프로젝트 3탄, HW] turtlebot3로 SLAM, Navigation 구현 (2020 Summer) (0) | 2020.09.09 |