![[딥러닝 프로젝트] Medical Imaging 모델 Fine-tuning 고난기: 0~1주차 혼란](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdEnwmA%2Fbtq5Qqf3sE5%2FIsSeQJ8KVMUBqbrdkioRWk%2Fimg.png)
이 글은 필자가 학교 수업 수강중 딥러닝 프로젝트 과제를 하면서 혼자서 파인튜닝을 한 고난기를 적은 여정입니다. 모델 튜닝을 하여 제출하는 과제이기에 제 자신이 한 머릿속 고민들과 아이디어들을 적어보고 싶어 만든 글이라 개념 설명은 따로 하지 않았습니다. 편하게 봐주세요!
완성된 모델 링크입니다.(완벽한 모델은 아니니 개발은 이렇게 진행된다고 감을 잡으시는 용도로 좋을 것 같습니다.)
매일 성능을 작성하였습니다.(Colab PRO를 구매해서 제대로 써보고자 매일 모델을 학습시키고 있습니다.) epoch마다의 학습 중 가장 성능이 뛰어날때/일반화가 잘 되었을 때를 뽑았으며 현재 1주차 진행중입니다. 6/1일까지의 목표: 75 ~ 80%
- 5/26일 58~59%
- 5/27일 50~100% 과적합 상황
- 5/28일 62~68%
- 5/29일 62~68%
- 5/30일 62~68%
0주차. 들어가기 전 딥러닝 모델 소개
- Goal: 교수님께서 제공해주신 Medical 데이터셋을 바탕으로 이를 분류하는 CNN 모델을 작성하라!
- 모델 전체: 간단한 CNN 구조, 작업이 많이 들어가야 할것으로 보인다. 기본적인 데이터 로딩 및 간단한 CNN 구조는 제시된 상황이다.
일단 모델을 뜯어 고쳐보고자 하는 욕심에 바로 뛰어들었다. 수작업으로 Train set과 Validation set을 나누고(일단은 4:1로 분류) 처음 돌렸을 때 성능은 다음과 같았다. 예상은 했지만 생각보다 낮은 Train, Validation set 성능이라 목표를 80까지 잡은 상황이었다.
Train Accuracy : 78.33333333333333
Validation Accuracy : 60.67415730337079문제점을 생각하면 다음과 같다.
- 과적합이 되어있다. Generalization이 필요하다!
- 위의 Validation Accuracy를 바탕으로 한 정확도가 매우 낮다.
이를 바탕으로 잡았던 아이디어들은 다음과 같다.
- 모델 구조 뜯어고치기. 가능하면 FPN을 구현하여 괜찮게 구현하고 싶다.
- 모델 데이터셋을 늘려야 할 것 같다.
- Generalization 처리해야 한다.
1주차. Fine-tuning 아이디어 구체화
위에 있던 아이디어를 구체화하기 시작하였다.
- 모델 구조 뜯어고치기. 가능하면 FPN을 구현하여 괜찮게 구현하고 싶다.
- Encoder/Decoder 구조 <- 굳이?라는 생각이 든다.
- (더 수정 필요) ResNet 구조
- 모델 데이터셋을 늘려야 할 것 같다.
- (두번째로 작업중) K-fold Cross Validation -> RAM 문제로 보류 -> 문제 해결로 다시 작업 시작
- (첫번째로 작업중) Data Augmentation: Noise 추가/TenCrop/FiveCrop -> 오히려 혼란만 초려 -> 제거
- Data Augmentation: r채널 한개에서 rgb 세개의 채널 모두 학습 -> transform 함수 맞는지 확인필요 -> 코드 수정 완료
- Data Augmentation: HorizontalFlip
- Generalization / Regularization
- L2-Norm 파라미터 추가
- 추가 옵션) DropOut
- Hyper-Parameter(항상 진행중)
- Learning Rate 조정
- Batch size 조정
모델 구조를 뜯어보고 싶었다. 생각보다 모델을 뜯어고치기에는 파라미터가 너무 많다. 일단은 다른 부분들부터 늘려보자고 마음을 먹었다. 뜯어고치기에는 다른 부분들도 엉망이라 데이터셋부터 늘려서 하나씩 찬찬히 해야겠다고 마음을 먹었다. 할 수 있는 것부터 찬찬히 하려한다.
(보류) 1주차 1. 모델 구조 뜯어고치기
5/27일 오전: 현재는 FPN을 구현하고 싶다는 생각이 든다. 그래서 FPN에 사용되는 주요 구조를 뜯어보고 내 환경에 맞게 설정해보려 한다. FPN의 FPN을 만들기 위해서는 Encoder/Decoder 구조에 ResNet을 적용한 구조가 많이 보인다. 이를 바탕으로 수행해보려한다. 음 먼저 Encoder/Decoder 구조를 먼저 작성해보려고 한다. 그 위에 ResNet구조를 얹는게 쉬우니까..! FPN 구조는 Feature Pyramid Network의 줄임말로 FPN과 관련된 여러가지 그림이 있는데 이를 모두 응용한 맨 마지막 그림임을 알 수 있다.

FPN 구조가 사실 생각보다 되게 오래된 구조이다. 그래서 이걸 도대체 왜 지금 쓰고 있는지 궁금해할 수도 있을것이다. 내가 생각한 이유는 다음과 같다.
- 학교 과제라서 RAM 지원 자체가 없다.
- 학교 수업에서 배운 plain한 ResNet 구조를 응용한 구조라서 적용해보고 싶었다.
- 분류 task이므로 Encoder-Decoder 구조가 머릿속에 꽂혔다.
이 정도로 정리할 수 있을 것이다. 1번은 핑계이기도 하지만 안해본걸 하고 싶은 욕심에 구현해보고자 한다.
-> 5/27 오후: 다시 생각해보니까 이건 3개의 채널이 아니라 1개의 채널에서 나타나는 분류이다. 굳이 저렇게 해볼 필요가 없다고 판단되었다. 일단은 ResNet 간단하게 구현 먼저 해보려한다. 너무 깊게 갈 필요가 없어보인다.
-> 5/27 저녁 ResNet 구조 완성 (여기서부터는 프로세싱 양이 많아서 epoch=20으로 설정)
ResNet50과 비슷하게 구현해보았는데 되게 흥미로운 결과가 나왔다. 사실 하면서 자꾸만 Google Colab에서 학습이 안된다고 해서 PRO를 구매하게 되었다. GPU가 아닌 TPU환경이 있어서 이게 뭔가 했더니 TPU는 구글에서 만든 NPU라고 한다. ResNet를 구현해본 결과는 다음과 같다.
# Epoch : 20 /20 100.0 49.25
일단 엄청난 과적합이 일어났다. 아무래도 데이터 부족인데 Deep한 모델이라 바로 학습된 것같다. K-Fold Cross Validation을 빨리 구현해야겠다고 느끼게 되었다. ResNet을 조금 더 가볍게 만들어 Generalization이 성공적으로 이루어야함을 느꼈다.
-> 5/28일 저녁 DropOut 구현
Generalization을 구현해야겠다고 마음먹어 Dropout 코드를 넣기 시작했다. 코드 넣는건 쉬워서 금방 넣었다. 다만 고려해야할 점은 크게 두가지였다. dropout p와 위치. 위치는 cs231n에서 제안한 느낌을 사용하고자 했다. cs231n에서는 Convolution - Batch Normalization - Activation - Dropout - Pooling 이라고 친절히 명시되었기에, ResNet은 냅두고 그 전체 틀의 위치에 dropout을 하나씩 넣기 시작해서 총 4군데에 넣었다. 그리고 가장 중요한 p 설정을 위해 일반적인 p=0.3 기준으로, 0.2와 0.3, 0.4를 모두 시도해보았다. 실행결과는 다음과 같다. (물론 데이터셋이 1K 미만이라 성능은 다를 수도 있지만 공부를 위해 전체적으로 해보고 싶었다.)
# Epoch : 13 / 20 64.34 59.7
오 생각보다 결과가 나쁘지 않다. 근데 너무 전과 동일해져서 기분이 나쁘긴 하다. 과적합에서 벗어나서 조금은 기쁘다. 근데 Train set이 100에서 저렇게 확 63~65%로 내려가는게 너무 많이 넣어서 그런가 싶어서 p 설정하는 김에 조금 더 줄이기로 생각을 해보았다. 일단은 남은 p 성능을 조사해보면,


이런 성능을 보며 p=0.3으로 귀결했다. (역시 사람들이 추천하는 파라미터 예시는 그만한 이유가 있다고 또한번 느꼈다.) 그래서 dropout 의 성능에 다시 집중해보았다. 4개를 넣었는데 ResNet 구조상 큰 지점에서 한번씩 넣어줘서 총 4번 넣게 되었다. 너무 많은 것 같아서 일단 맨 처음 한번만으로 처리해보았다. (원래 ResNet과 Dropout이 관계가 없는데 그냥 넣어봤던 거라 혹시나 빼보았다)

역시 ResNet을 볼 것이 아니라 Conv-Batch Normalization-Activation function 등의 일련의 관계를 봐야하나보다. 확실히 차이가 컸다. 그냥 넣기로 마음을 먹고 초심으로 돌아가 epoch=60으로 설정하고 크게 한번 돌려보았다.
# Epoch : 19 / 60 68.36 62.69
역시 20까지는 괜찮다가 갈수록 과적합을 보였다. 보면서 ResNet 구조를 더 경량화해보는 건 어떨까라는 생각이 들었었는데, 다시 생각해보니 Layer가 적을수록 과적합이 될 가능성(그 데이터셋에 맞춰질 것이므로) 이 높다는 걸 파악하였다. 그래서 이 ResNet 구조를 고수하되 데이터 중심으로 다시 확인해보는게 낫겠다는 생각이 든다. + PRO로 하니까 엄청나게 무거운 모델도 휙휙 잘돌아간다. 만원의 행복을 충분히 느낄 수 있는 기회였다. 근데 다시 원점으로 돌아왔다는 느낌이 들어 한편으로는 허무하다.
내일(5/29)부터는 데이터에만 집중해보려고 한다. 무슨 수를 써서라도 다음주는 75~80의 성과를 내야한다.
(진행중) 1주차 2. 데이터 개수 늘리기Data Augmentation: Horizontal Flip & K-fold Cross Validation & 데이터 전처리
데이터 개수가 굉장히 적었기 때문에(Train set 데이터셋이 각각 143개로, 총 286개 정도이다.) 이를 늘리는 것이 굉장히 절실한 문제임을 알 수 있었다. 몇줄의 코드만으로 쉽게 HorizontalFlip을 구현하였다. HorizontalFlip만 구현해서 데이터셋은 2배가 되었고 총 572장의 데이터셋을 만들어냈다.
# Epoch : 56 /60 70.45 59.7
과적합의 늪이 시작될 기미가 보인다. 일단은 이 링크를 참고하여 이를 해결해보려한다. K-fold Cross Validation은 skorch로 구현하고자 한다. skorch로 k-fold cross validation을 실행하려는데 생각보다 에러가 많이나고 무엇보다 RAM 문제가 커서 학습이 잘 되지 않는다. + 5/27: 다시 생각해보니 Train, Validation set이 모두 공개되어있어야 하는데 나뉘어져있다. 실현하려면 train_test_split 코드를 도입해야 한다.
-> 다시 확인해보니 r채널에서만 제한되어 모델이 작동되고 있었다. 5/27 3:31PM 저장 건에는 3개의 채널로 하려 하였으나 코드 상의 이상으로 보류, 일단은 rgb 채널의 평균에서 작동시켰다.

구현해보니 역시나 영향이 있었다. 일단 과적합이 줄어들었고 학습이 덜 된 것으로 보였다. 그래서 epoch=120으로 처리하여 다시 학습해보았다.(epoch를 120이나 하다니.. 빨리 데이터셋 늘려야겠다) 그리고 특정 부분에서 validation set 성능이 낮은 것 같아 validation dataset에 설정되어있는 shuffle을 True로 설정했다.
# Epoch : 100 /120 67.83 64.18
대충 64~ 67% 사이의 성능을 도출함을 알 수 있다. epoch가 60 ~ 70 즈음이 generalization에 최적화된 구간인 것 같고 그 이후로 과적합이 나타나는 양상을 볼 수 있다. 음 데이터 처리는 어느정도 된 것 같고 모델 Layer를 조정해보아야겠다.
-> 5/28일 오전: RGB채널에서 모두 작동되어 3개의 채널이 input으로 들어가 작동되게 하려고 코드를 수정했다.

수정하여 코드를 작성하니 엄청난 과적합 상태가 만들어져있었다. 원래 572장으로 무리인 줄 알고 있었는데 이정도 일줄은 몰랐다. 이제는 Data Augmentation에 초점을 맞춰서 K-Fold Cross Validation, Noise가 추가된 데이터셋 추가, L2-Norm Generalization 등 일반화가 되도록 코드를 다시 전체적으로 갈아엎어야겠다.
-> 5/30일 오전: transforms.Compose 함수를 바탕으로 Data Augmentation을 구현해보려고 했다. 두가지를 생각하고 있었다. FiveCrop과 GaussianBlur이다. 근데 계속 생각을 해보니 GaussianBlur는 안그래도 흰검만 존재하는 이미지에 혼란만 초래할 것 같아서 애초에 제외했다. 그래서 남은 FiveCrop을 구현하여 572장의 train set을 2860의 trainset으로 변경해버렸다. 하지만 계속 고민이 되었던 건 사실이다. 왜냐하면 (600,600)에서 (400,400)에서 줄이는데 중요한 데이터들이 다 사라진다는 느낌이 계속 들었기 때문이다. 2/3 크기로 줄어드는 부분에서 계속 고민이 되었던 건 사실이다. 그래서 60번 epoch로 학습을 돌렸는데
# Epoch : 5 / 60 61.75 53.73
돌고돌아 이 결과라는게 조금 이상해서 다시 1주차 마무리로 전체를 마무리하고자 한다.
(완료) 1주차 3. Batch Size 처리 & Optimization Learning Rate 처리
일단 Batch Size 너무 작았다. 이게 과적합이라는 문제를 야기하는 것 같았다. 이 때문에 Batch Size를 20에서 70으로 확 늘렸다. 이와 더불어 Optimization이 업데이트 되지 않는것같아 보였다. 이또한 코드를 넣어서 처리를 해주었다.
# Epoch : 55 /60 63.64 58.21결과는 이와 같이 나왔다. 이로써 나는 78%의 과적합이 아닌 그냥 원래 61~2%의 성능을 가졌음을 알 수 있었다! Learning rate는 우선 0.0001로 조정해놓았고, Batchsize도 70으로 확 늘렸지만 개선의 여지가 더 보여서 일단은 완성되지 않은 것으로 냅두었다. (현재는 0.0001,144으로 작성중이다)
Optimization Learning Rate를 0.0001에서 0.001, 0.0005로 늘려보았다. 우선 0.001로 늘린 결과는 다음과 같다.


-> 5/29일 오전: 일단 lr을 고정한 다음 L2-Norm Regularization을 추가하려 설정을 했다. epoch=60으로 처리한 결과는 다음과 같다.
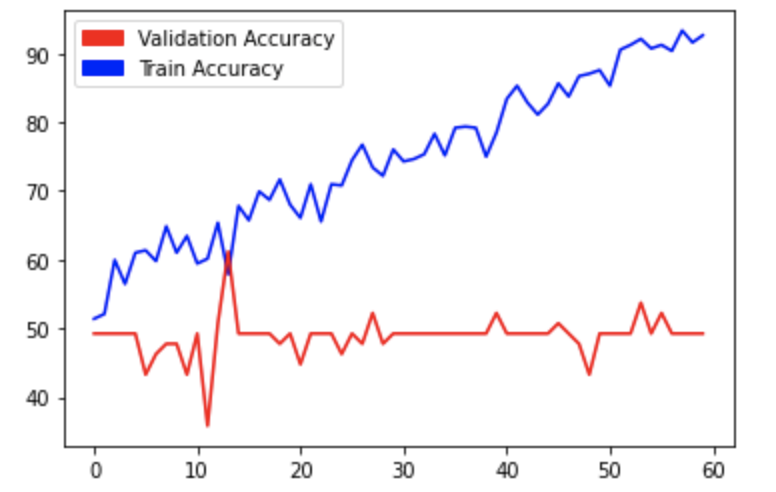
이제는 거의 할 수 있는 걸 다했으니 문제는 바로 데이터라 판단했다.
1주차 마무리
일단 모델을 전체다 이해를 했고 정확도가 올라가지 않은 이유는 데이터 전처리 문제 + 데이터가 부족한 이유같다. 다시 확인하면서 다음과 같은 일들을 처리하고자 한다.
- 모델 구조 뜯어고치기. 가능하면 FPN을 구현하여 괜찮게 구현하고 싶다.
- Encoder/Decoder 구조 <- 굳이?라는 생각이 든다.
- (더 수정 필요) ResNet 구조
- Data Preprocessing
- K-fold Cross Validation
- Data Preprocessing: RGB채널 각각이 아닌 한 채널로 처리
- Data Augmentation: HorizontalFlip
- Generalization / Regularization
- L2-Norm 파라미터 추가
- 추가 옵션) DropOut
- Hyper-Parameter(항상 진행중)
- Learning Rate 조정
- Batch size 조정
일단 데이터 전처리 문제가 제일 문제이고 그 다음으로 모델을 봐야겠다. K-fold Cross Validation을 구현하고 train_test_split을 조정해야겠다. 전체적으로 다 수정할 필요가 있다.일단 1주차는 이렇게 종료
'Projects > Projects' 카테고리의 다른 글
| [딥러닝 프로젝트] Medical Imaging 모델 Fine-tuning 고난기 : 3주차 마무리 및 문제점들/보완점들 (0) | 2021.06.12 |
|---|---|
| [딥러닝 프로젝트] Medical Imaging 모델 Fine-tuning 고난기: 2주차 차차 정리 (0) | 2021.06.07 |
| [웹개발] Nodejs-Firebase-Bootstrap을 이용한 프로젝트 CIYN 소개 (0) | 2020.12.18 |
| [JAVA] 네트워크를 통한 실시간 그림판/채팅방 구현 (2) | 2019.12.27 |