![[Generative Model] Variational AutoEncoder 1. Basic: AE, DAE, VAE](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F6tUdd%2Fbtrm7NyI4yW%2FekTQTKHKE22A4FltH344EK%2Fimg.png)
이 글은 필자가 주재걸 교수님의 2018-1 Image Generation and Translation 강의를 듣고 추가 블로그 참고1, 참고2, 참고3, 참고4를 읽으면서 정리차 작성한 글입니다.
강의를 듣게 된 경위: 이용해야 할 개념에서 Image와 같이 2D 개념에 적용한 예시가 없어서 이를 2D에 적용하면서 나타낼 수 있는 문제점들이나 인사이트들을 다시 확용하고자 image generation task에 연결하고자 듣게 되었다.
- 220130. VAE loss function 자세히 내용 보충
- 220319. Generative model ) Latent variable model 내용 보충
Generative model?
: Training data의 distribution을 학습하여 새로운 data instance를 생성해내는 모델
Generative model의 활용 사례
: Pure Generation(순수한 이미지 생성), Image Translation(대충 그린 그림을 이미지로), Super resolution etc. (학습 데이터로 생성된 새로운 이미지들을 Data augmentation 에 적용하여 모델 학습에 도움을 줄 수 있다.)

Generative model ) Latent Variable model
: observation(train dataset)에 대한 transformation을 통해 그들의 unobserved/latent variable을 생성해내는 방법이다. 영문이 더 이해하기 쉬워 영어 서술을 들고 오자면,
- Specify the generative process in terms of unobserved/latent variables and the transformation that maps them to the observation.
- Trained with maximum likelihood (usually with some approximations) -Deepmind X UCL lecture에서
Auto-Encoder → Denoising Auto-Encoder → Variational Auto-Encoder
🎈 Auto-Encoder
#UnsupervisedLearning #MLDensityEstimation #ManifoldLearning #GenerativeModelLearning
- Very basic version of Image generation
- Goal: Dimension Reduction
- Manifold Learning. input data의 feature를 기깔나게 추출해야 하는 목표를 가진다. 분포 생성이 아니다. 그냥 단지 생성하는 모델.
- Model structure: 입력(x)과 출력(x')이 같은 구조
- Encoder를 통해 (image의 특징만을 저장해놓은) Feature vector를 생성 → Manifold Learning
- Bottleneck z (=Latent variable = Feature = Hidden representation)
- Decoder를 통해 이미지를 생성 → Generative Model Learning
- Loss function: Mean of results from Monte Carlo samples for gradient calculation

https://user-images.githubusercontent.com/24144491/50323472-1a016400-051d-11e9-86b7-d8bf6a1a880f.png - Reconstruction loss에 따라 다른 Loss function
- Gaussian/MSE loss
- BCE loss

- Gaussian/MSE loss
- Reconstruction loss에 따라 다른 Loss function
- 학습 방법
- Training Process: Encoder-Decoder 모델로 정상적으로 학습
- Generation Process: training process에서 나오는 Feature vector를 따로 학습하여 sampling 가능한 모델 생성
- Sampling하여 image generation이 가능하도록 처리
- 활용: Input data의 feature를 추출할 때, Dimension Reduction task 등

🎈 Denoising Auto-Encoder (DAE)
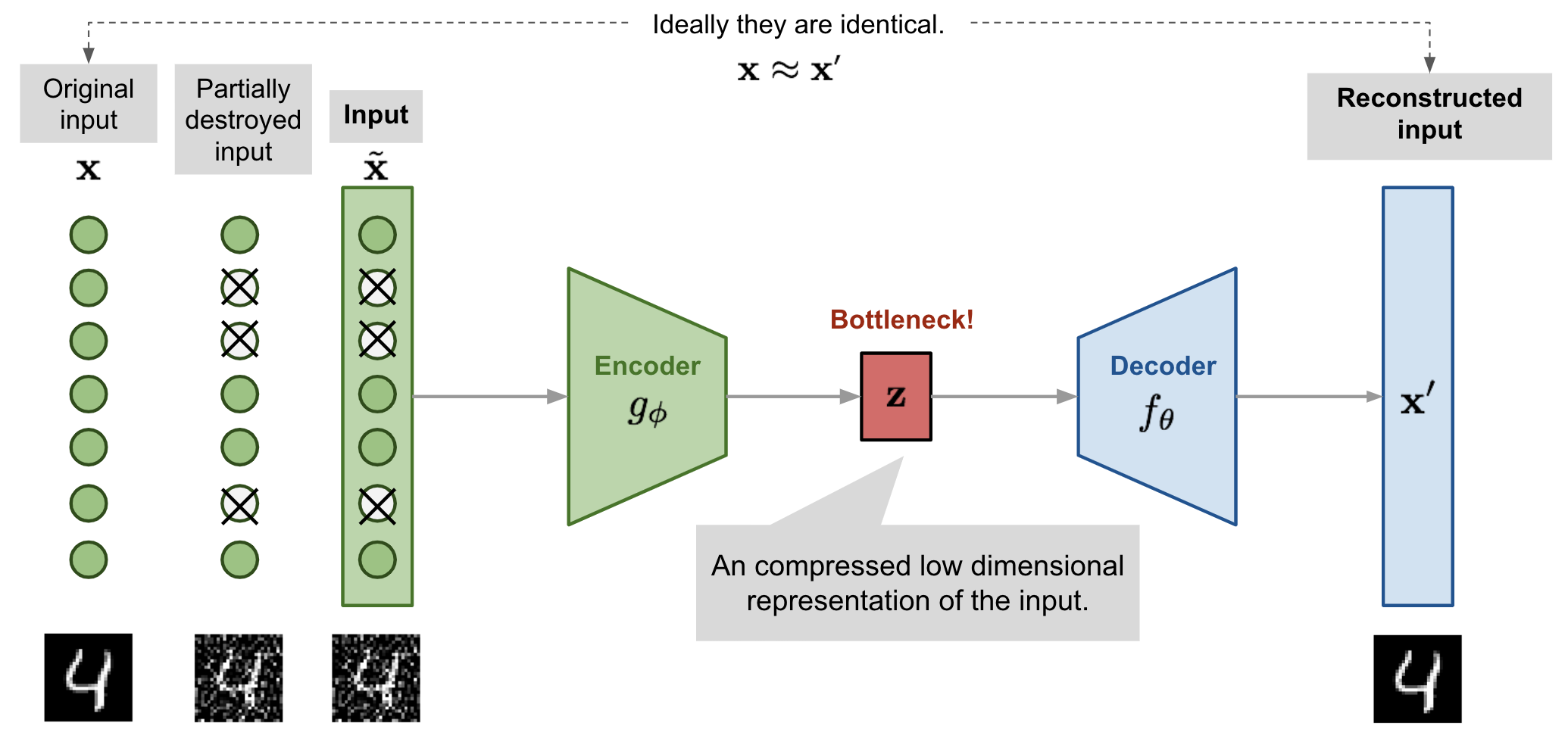
- Auto-Encoder에 input부분에 random noise를 추가
- input을 훼손하여도 보존하도록 설정 (꼭 input 쪽에 noise를 추가할 필요는 없다. 뒷단에도 추가해보자: VAE)
- Noise의 허용정도를 어떻게 적용해야 하는 것일까 (이 모델에서는 random sampling 된 gaussian noise로 처리 but NN이 스스로 학습하여 값을 생성하도록 하자: VAE)
- Model structure: 입력(x+noise)과 출력(x')이 같은 구조
- Encoder를 통해 Feature vector를 생성 → Manifold Learning
- noise를 추가해도 Manifold상에서는 똑같은 곳에 분포된다는 가정이 존재한다.
- Bottleneck z (=Latent variable = Feature = Hidden representation) z = e(x)
- Decoder를 통해 이미지를 생성 → Generative Model Learning
- Loss function: L(x, x'), output to be close to input
- Encoder를 통해 Feature vector를 생성 → Manifold Learning
🎈 Variational Auto-Encoder (VAE)
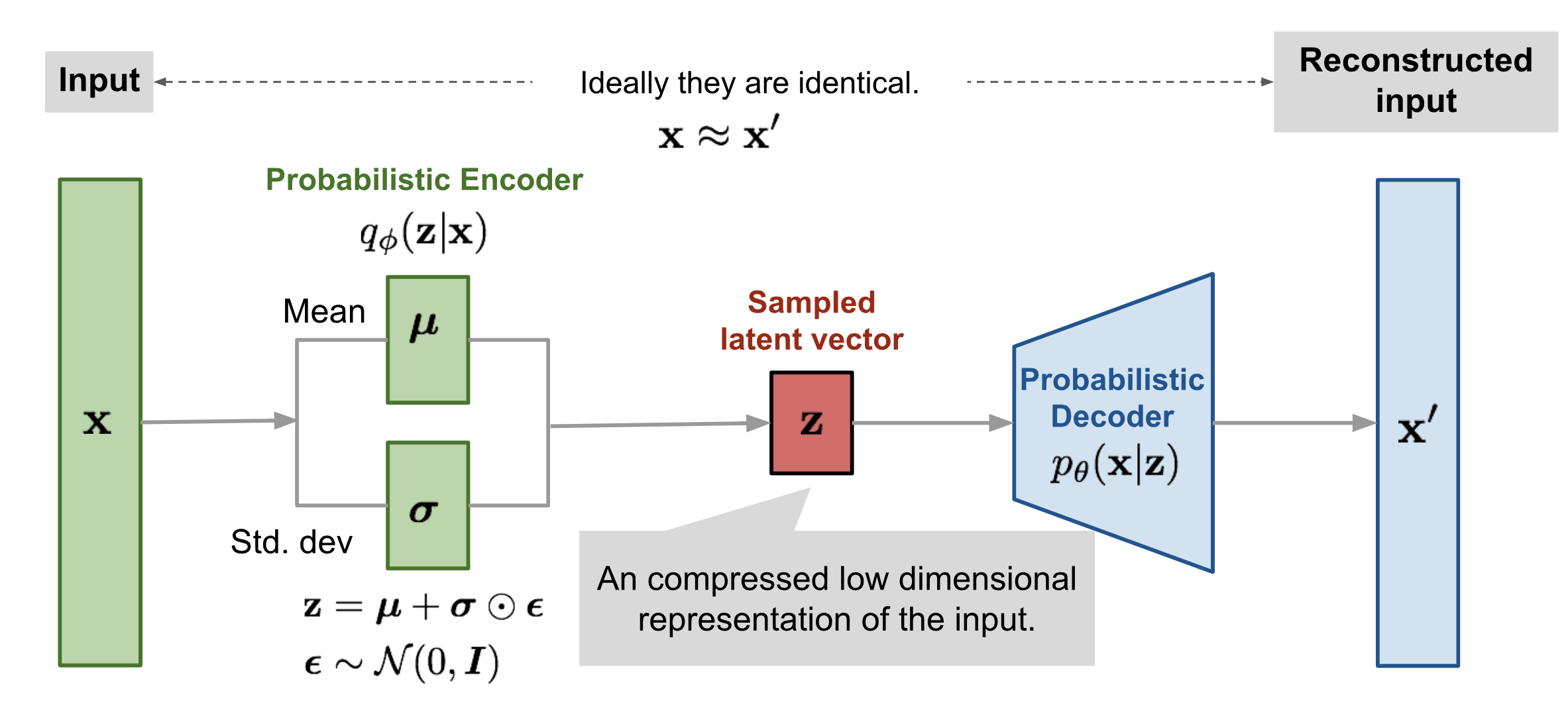
- Auto-Encoder에 input말고 다른 곳에 noise 추가
- Goal: Distribution 생성을 통한 Generation.
- Generative Model. 제공해주는 Vector z값 바탕으로 기깔난 image를 생성(: 기깔난 Decoder 학습) ⇒ Latent vector z값 바탕으로 기깔난 image를 생성 ⇒ 데이터 x가 나올 확률을 출력해야 한다.
- 뒷단(Encoder, Decoder 사이)에 noise를 추가해보자
- noise 값 생성: NN이 스스로 noise를 뽑는 방식으로
- 학습: Encoder, Decoder / Inference: Decoder
- Encoder에서는 Sampling하는 과정에서 Variational Inference로 target distribution을 잘 나타내는 distribution 찾기 → z sample 잘 만들기
- Latent distribution p(z|x)
- Latent distribution p(z|x)
- Controller z(= Latent variable)
- 단순히 샘플을 생성해내는 것이 아닌 컨트롤러로 생성된 이미지를 조정하는 z vector: sampling하는 프로세스로 비슷한 점들끼리 모이는 방식으로 학습
- Prior 값이 normal distribution을 띈다고 가정하고 sampling시 sampling된 값은 manifold를 대표하는 값이 될 수 있다.
- Deep Neural Network의 간단한 레이어로도 복잡한 latent space를 익힐 수 있다.
- 단순히 샘플을 생성해내는 것이 아닌 컨트롤러로 생성된 이미지를 조정하는 z vector: sampling하는 프로세스로 비슷한 점들끼리 모이는 방식으로 학습
- Decoder를 통해 이미지를 생성 → Generative Model Learning
- Loss function: Encoder에서 나오는 Sampling loss + Decoder에서 나오는 이미지 생성 Loss → ELBO 최대화
- Encoder에서는 Sampling하는 과정에서 Variational Inference로 target distribution을 잘 나타내는 distribution 찾기 → z sample 잘 만들기
- Reparamertization trick: Backpropagation이 가능하도록 수행
- MNIST를 활용한 Pytorch Code Implementation
➕ Addition
- Manifold Learning: 고차원 데이터를 데이터 공간에 뿌리면 sample 들을 잘 아우르는 subspace: latent space가 있을 것이라는 가정에 데이터의 차원을 축소(dimensionality reduction)시키는 일
- noise를 추가해도 Manifold상에서는 똑같은 곳에 분포된다는 가정이 존재한다.
- Prior값이 normal distribution 값을 띈다고 가정하고 Sampling시 Sampling된 값은 manifold를 대표하는 값을 가질 수 있다.
- ML Density Estimation:
- Negative ML
- Variational Inference: 이상적인 sampling 함수를 구하기 (True posterior를 approximate하는 z를 생성하기)
- Training dataset에 있는 input data와 유사한 분포를 가지기
- ELBO(Evidence LowerBOund) (ELBO 최대화)
- KL Divergence: 두 확률분포 간의 거리 측정 (KL Divergence 최소화)
- Training dataset에 있는 input data와 유사한 분포를 가지기
➕ Q & A
- Q. Auto-Encoder는 왜 unsupervised learning인가?
- A. AutoEncoder는 비교사 학습방법을 따르기 때문에