![[Basic] Activation Function/Loss Function/Evaluation metric](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcDl4TQ%2Fbtrs21SLr86%2FXKjQTPuK1HZdTSKaZK09lK%2Fimg.png)
본 글은 필자의 이해를 돕기 위해 작성된 글입니다. 참고 링크: 링크1
🐤Loss Function 과 Evaluation Metric 차이점
간단히 말해서 Loss function은 딥러닝 모델 학습시 성능을 높이기 위해 minimize/maximize 시켜야 하는 지표이고, Evaluation metric은 여러 딥러닝 모델들 중에 좋은 성능을 확인하기 위해 쓰이는 지표입니다.
예를 들어 classification 문제라 하면 모델의 loss function은 대체적으로 crossentropyloss 으로 분류의 지표를 표시한다면 모델 들 간의 성능을 확인하기 위해서는 evaluation metric이 accuracy가 되어야 한다.
딥러닝 모델의 parameter estimation method 중 하나인 Maximum likelihood Estimation(MLE)는 이를 구현하기 위해 Maximum A Posterior Estimation(MAP)를 활용한다. 참고링크
🐤 Activation Function 종류
- ReLU
- Softmax
- 중간 층의 출력값에 대표적으로 사용되며, 0~1 사이의 값을 출력합니다. 주로 binary classification에 사용되어 0.5보다 크면 해당한다고 분류됩니다.
- Sigmoid
- 출력함수에 최종 class 별 0~1사이의 값으로 출력됩니다. categorical classification에 사용되어 가장 높은 probability를 가지면 해당한다고 분류합니다.
- 왜 Classification에서는 BCE가 어울리는가? Gradient 적용시 Classification의 마지막 activation function인 sigmoid function에서 MSE는 Gradient vanishing이 적용된다.
🐤 Loss Function 종류
Loss는 Negative Log likelihood를 바탕으로 정의되며 대표적으로 MSE, BCE가 존재한다.
- Negative Log likelihood (NLL)
| Loss function | MSE | BCE |
| Prediction | ||
| Output distribution Assumption |
Gaussian distribution (sigma=1) | Bernoulli Distribution |
- CrossEntropy(CE)
- Bernoulli Distribution, Probability
- Binary Cross-entropy(BCE)
- Categorical Cross-entropy
- Bernoulli Distribution, Probability
- Mean Squared Error(MSE)
- Gaussian/Normal Distribution(sigma=1), Probability
- Gaussian/Normal Distribution(sigma=1), Probability
- 번외
- Multitask Loss
- Regularization loss: for robust model add regularization loss and get multitask loss ex. L1, L2 Regularization loss
- Mask R-CNN loss function
- Variational Auto-Encoder
- Reconstruction loss: Loss to check of how well the image has been reconstructed from the input
- Multitask Loss
🐤 Evalution Metric 종류

Confusion matrix→ Accuracy, F1 score
- Accuracy
- F1 Score
- Precision과 Recall의 조화평균이며 주로 분류 클래스 간 데이터가 심각한 불균형을 이루는 경우에 사용된다.
IoU → Precision/Recall → PR → AP → IoU에 따른 mAP
- IoU(Intersection over Union)
- IoU가 threshold를 만족한다면(0.5 이상이면) 제대로 검출(TP)되었다고 판단한다. 만약 0.5 미만이면 잘못 검출(FP)되었다고 판단한다.
- Confusion matrix에 따른 Precision/Recall
- Precision정밀도: 검출 결과들 중 옳게 검출한 비율
- Recall재현율: 실제 옳게 검출된 결과물 중 제대로 예측한 것의 비율
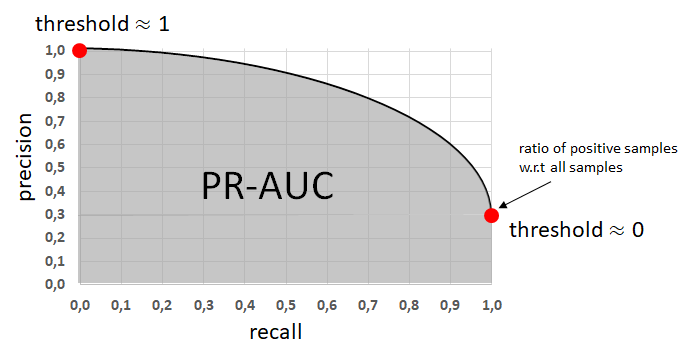
- Precision-Recall 곡선(PR곡선): Precision, Recall은 서로 반비례 관계를 가지며 PR 곡선에서는 recall 값의 변화에 따른 precision 값을 확인할 수 있다.
- AP/AR(Average Precision, mAP/mAR) = PR-AUC
- Object detection의 대표적인 성능 지표로 사용된다.
- mAP(mean Average Precision): 각 클래스당 AP의 평균
- AP/AR(Average Precision, mAP/mAR) = PR-AUC
- Precision정밀도: 검출 결과들 중 옳게 검출한 비율
'AI, Deep Learning Basics > Basic' 카테고리의 다른 글
| [Logger] TensorboardX 사용하기 (0) | 2022.02.19 |
|---|---|
| Training tip 정리 (0) | 2022.02.16 |
| [기초] 딥러닝 성능 높이기: 층을 깊게 하는 것에 대하여 (0) | 2022.01.15 |
| [Deep Learning] 헷갈리는 기본 용어 모음집 (1) (0) | 2022.01.11 |
| (작성중) [기초] 3. Overfitting/Underfitting 및 Regularization일반화/일반화 기법 (0) | 2022.01.09 |