![[Deep Learning] 헷갈리는 기본 용어 모음집 (1)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbHrZGm%2FbtqyfsLHxDS%2FSb2T9sD2ggeTpo7W8l7M6K%2Fimg.png)
본 글은 필자가 자꾸 헷갈려하는 용어들을 모아놓은 글입니다. 글의 순서가 매끄럽지 않을 수 있다는 점 참고해주세요.
헷갈리는 용어들을 생각날 때마다 업데이트 한 글입니다.
CNN이란?
: (Convolution + Subsampling) 의 연속 + (Fully-Connected)
(Convolution + Subsampling) 을 통해 Feature Extraction을 수행한 후, (Fully-Connected)를 통해 분류를 실행하게 됩니다. 이런 일련의 구조를 통해 계층구조를 형성하는데, 이를 compositionality라 칭합니다.
Convolution 과정을 통해 Image * filter를 통해 Convolved Feature를 뽑게 된다.
- tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
- Zero-Padding: 가장자리의 Feature를 뽑아내기 위해 가장자리에 padding을 붙이게 된다.
- Stride: Feature를 뽑아낼 때, stride만큼 점프하여 계산하게 된다.
- Channel: 하나의 그림에 여러가지 특성을 뽑아낼 때 channel로 구성하여 뽑게된다.
Subsampling 과정을 통해 Convolved Feature(행렬)을 줄인다.
이 모든 것의 토대에는, 우리가 정하는 parameter의 값이 적어야 변수가 적어지므로, 적은 쪽으로 생각해야 한다.
Dropout이란?
인공신경망이 과적합되는 우려를 막기 위해 각 레이어에 있는 유닛들의 일부를 생략(값을 0으로 random하게 바꾸는 과정이다.)하는 과정을 뜻한다. 일반화하는데 아주 대표적인 방법중에 하나로 기본적으로 쓰이는 방법이다.
Filter란?
이미지의 특징을 찾아내기 위해 가지고 있는 파라미터를 뜻한다. 이를 Kernel이라고도 하는데, Input의 한 크기와 Filter로 Convolution을 거쳐, Feature Map의 한 값을 생성하게 됩니다.
Padding 이란?
입력데이터에 반해 나오는 Feature Map의 크기가 너무 작아지는 것을 방지하기 위해서 입력데이터의 크기를 처음부터 크게 하여 Feature Map의 크기가 작아지지 않도록 막는 역할을 합니다. 보통 패딩 값은 0이 됩니다.

Activation Map이란?
위에서 언급한 Feature Map에서 활성함수를 적용한 결과를 Activation Map이라 말합니다. 하나의 Hidden Layer의 최종 결과는 Activation Map이라고 합니다.
Pooling 이란?
Activation Map의 크기를 줄이거나 특정데이터를 강조하기 위하여 작동이 되는데, Pooling레이어를 처리하는 방법으로는 Max Pooling, Average Pooling, Min Pooling이 있습니다. 이를 통해 행렬의 크기를 감소하는 효과를 얻을 수 있습니다.
Batch란?
머신러닝 전반에 걸쳐서 작용되는 이야기인데, B**atch size**는 전체 데이터 안에서 내가 이용할 데이터 전체 개수를 의미한다.
만약 데이터가 1000개이고 batch size가 500이면, 한번(1 iteration)에 학습할 데이터 개수는 500이 되는 것이다.
batch * iteration = 전체 데이터 갯수
iteration은 나뉘어진 데이터 조각 하나를 학습한다는 개념이면, epoch는 모든 데이터 셋을 한번 학습한 횟수이다. epoch가 3이면 모든 데이터를 3번 학습했다고 볼 수 있다.
Batch Normalization이란?
CNN의 convolution이후 너무 커지거나 너무 작아져서 갈피를 잡기 힘든 값들을 정규화시켜 보기 쉽게 이용하려는 방법
위와 같이 이렇게 conv 작업 이후 계속해서 batch normalization을 해줘야 계산 자체로 부담가는 부분을 막을 수 있다.
Single Layer Network 의 과정은?
input * Weight + Bias > Relu(Activation Function) = Output 의 상황을 거친 Network를 의미한다.
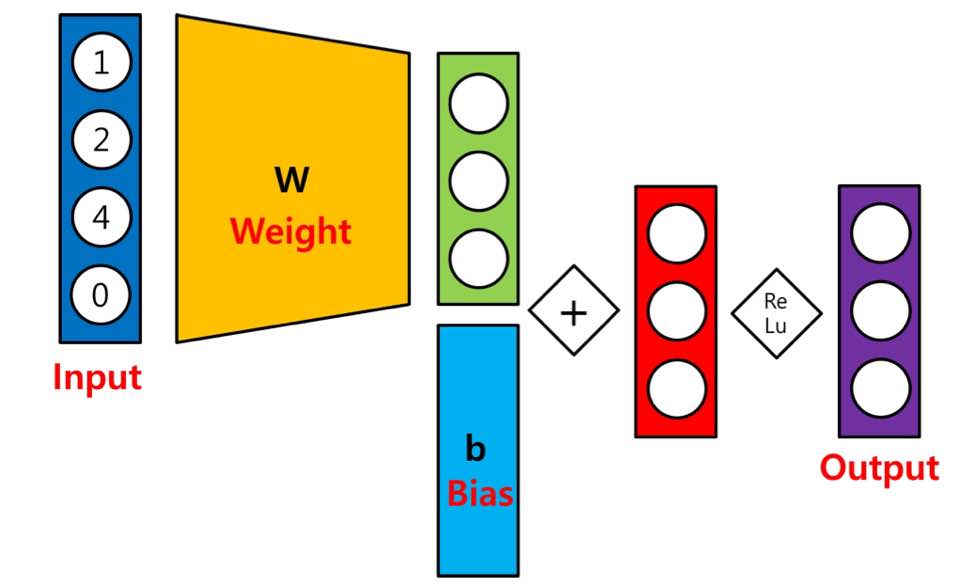
Activation Function
활성화 함수로, 여러가지 종류가 존재한다.
- sigmoid | 0~1사이의 확률을 나타낼 때
- tan(h(x)) | -1~1 사이로 음수를 고려할 때
- ReLU | 일반적으로 쓰이는 활성화 함수
- Softplus | 부러운 곡선을 요구할 때 자주 쓰인다.
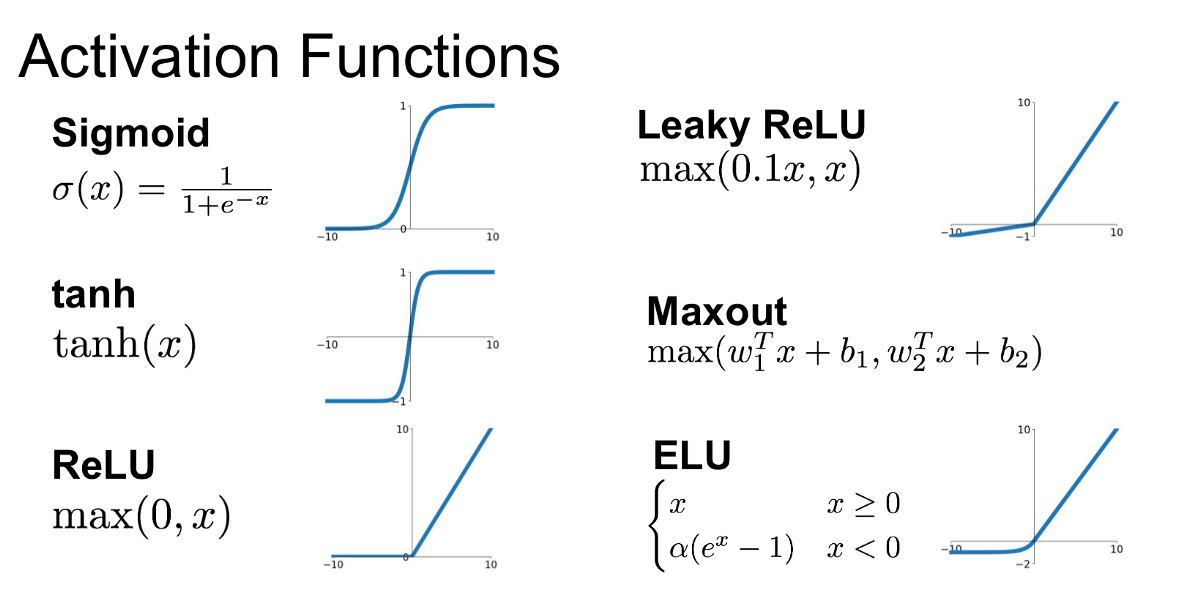
여러가지 함수가 존재하며, 데이터와 여러 조건을 고려하여 이용된다.
Local Response Normalization(LRN) 이란?
일정부분 강조하고 싶은 부분만 높게 activation하고, 나머지는 낮게 작용하는 방식이다.
Data Augmentation이란?
적은 데이터수를 늘리기 위해 작용하는 방법으로, 데이터에 일정부분 작용하여 나타난다. 대표적으로 Crop 하거나, Flip을 하여 데이터 수를 늘리게 되는데, Crop시는 데이터가 image인 경우 사진의 부분만을 잘라서 데이터로 취급을 하게 되고, flip시에는 앞, 뒤나 위, 아래로 뒤집어서 여러 데이터를 만들게 된다. 하지만 이와 같은 경우도 뒤집을 때, 데이터의 의미를 손상하는 경우가 있으므로 주의해야 한다.(이를 Label preserving이라고 하며, 대표적인 예시로는 숫자 그림을 들 수 있다.)
- a. No augmentation(= 1 image)
- b. Flip augmentation
- c. Crop augmentation
- c. Crop + flip augmentation
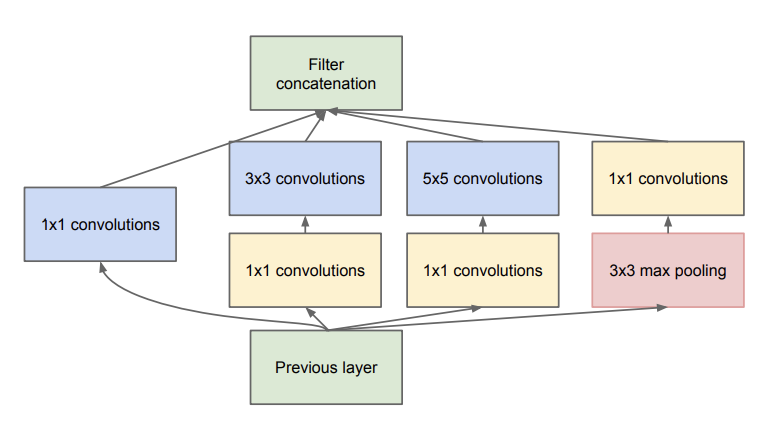
Inception Module이란?
현존하는 Convolution계산은 주위의 값들에 관하여 densely connected되어있는 것에 비해, 넓은 범위의 관련성을 적용하기 위해 나타난 Sparse Connectivity를 위해 등장하였다. 이는 4가지 작용을 통해 나온 결과값들을 합하여 작용한다.
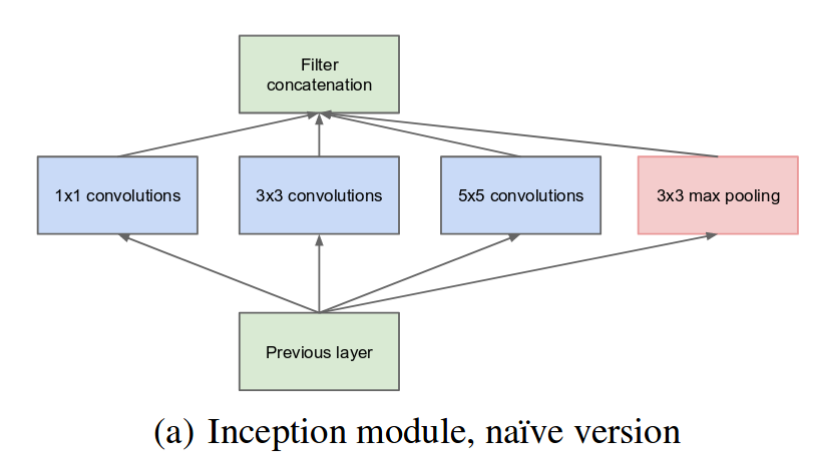
장하였다. 이는 4가지 작용을 통해 나온 결과값들을 합하여 작용한다. 여기서 심화된 버전은 여기서 나타나는 심각한 문제인, 정할 parameter가 많은 문제를 해결하기 위해 1 * 1 convolution을 넣어 줄여준다.
Localization 이란?
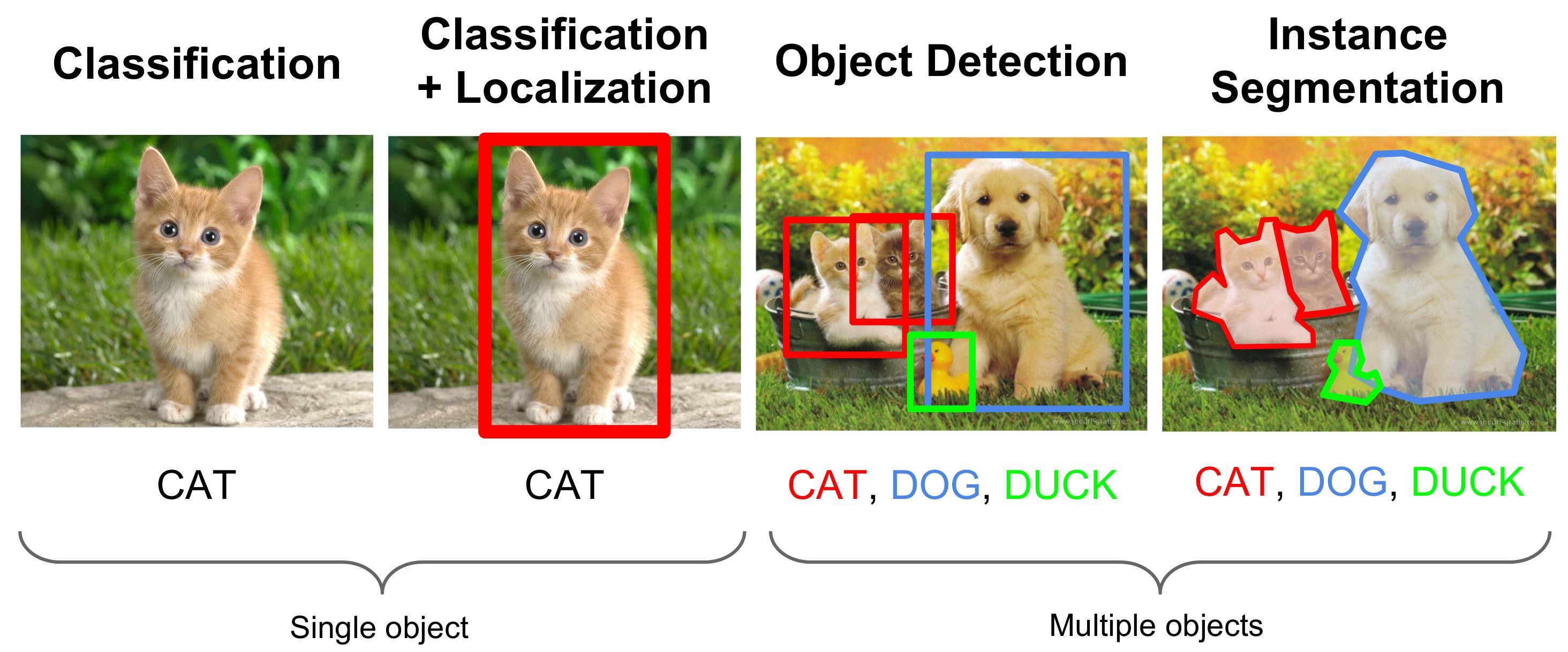
Localization은 Classification의 결과 분류되었다면, localization은 이 분류된 결과의 위치를 제대로 detect 함을 의미한다.
Self-Supervised Learning
self-supervision: Pretext task Network -(transfer learning)→ Downstream task network
unlabeled dataset를 input으로 받아 pretext task(사용자가 정의한 문제)를 network가 학습하게 하여 데이터 자체에 대한 이해도를 높이고자 함.
Pretext task에서 나온 pre-training 되어진 network를 downstream task(궁극적으로 사용자가 풀고자하는 문제)에 transfer learning 하는 방법
Pre-training vs Fine-tuning
fine-tuning: 기존에 학습되어져있는 모델(pre-trained model)을 기반으로 아키텍쳐를 새로운 목적에 맞게 변형하고 이미 학습된 모델 weights 로부터 학습을 업데이트하는 방법 =정교한 파라미터 튜닝
Fine-tuning 유형
- 미리 학습된 모델로부터 세세한 부분 수정(header를 새로운 것으로 교체 등)
- 다른 backbone을 추가하도록 모델을 수정
pre-training: 사전에 학습된 모델
Domain
source domain: 학습 데이터, target domain: 평가 데이터
Domain shift: source data와 target data이 많이 다른 상황에 domain shift를 통해 domain adaptation을 진행한다.
Model Compression
큰 모델을 작게 만드는 방법
- Pruning: 모델에서 중요도가 낮은 뉴런을 제거하여 직접적인 모델의 크기를 감소
- ex. Network Pruning
- Distillation: 작은 모델에 큰 모델의 정보를 전달해 작은 모델의 정확도를 향상시킴
Bounding Box
- Based on Grouping Super Pixel(eg.Selective Search)
- Based on Sliding Windows(eg. EdgeBoxes, Objectiveness in Window) > Anchor(Bounding box 개수 제한)
Reinforcement Learning
reinforcement learning: reward를 중심으로 작동
imitation learning: 어떤 특정 behavior 이 작동되도록 intelligent agent의 policy를 중심으로 작동 = Behavior Cloning(BC)
Object Segmentation = Object Detection(score) + Localization(position)
R-CNN: Region based CNN
Search Algorithm
Selective Search Algorithm: 영상은 계층적 구조를 가진다는 가정아래 bottom-up/Hierarchical Grouping 그룹화 방식 사용
- 초기 sub-segmentation 방법 수행
- Greedy 알고리즘으로 작은 영역을 반복적으로 큰 영역으로 통합(1개의 영역이 남을 때까지 반복)
- 기준: RGB, texture, 크기, enclosures
- 통합된 영역들을 바탕으로 후보 영역 만들기

Exhaustive Search Algorithm: 후보가 될만한 모든 영역을 샅샅이 조사
Spatial Pyramid Pooling
: Multi-Size Training
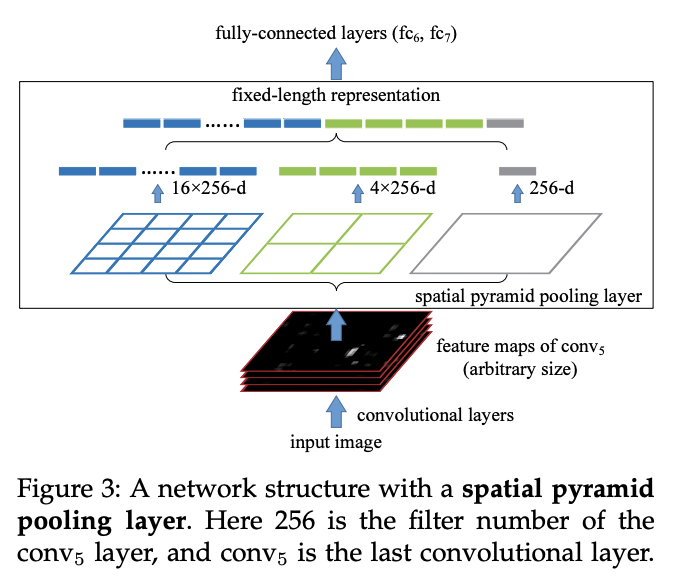
RoI Pooling Layer: Region of Interest - image를 section별로 나누어 max pooling 을 수행한다. > 거의 Max Pooling
FCN(Fully Convolutional Networks)
- 최종 Feature map을 32배, 16배, 8배 크기로 키움
- 키운 Feature map들을 합성곱 연산하여 픽셀별로 분류
Region Proposal Network(RPN): FCN에 포함되어있다.
: image를 받아 사각형 형태의 object proposal region과 objectness score를 출력해주는 역할을 한다.
동일한 크기의 sliding window를 이동시키며 window의 위치를 중심으로 사전에 정의된 다양한 비율/크기의 anchor box들을 적용하여 RPN 손실 함수가 낮은(IoU가 높은/객체 존재 확률이 높은 순을 추출)
- Extract Bounding Box
- Crop image by Bounding Box > RoI(Region of Interest) 생성
- Warp or Pooling to Make Right Shape
IOU로 계산 > Object localization에서 두 개가 같이 높을 때 Non-Maximum Suppression, Classification은 높은 거
추가. FPN vs. FCN vs. FC layer
- Feature Pyramid Network(FPN)

- Fully Convolutional Networks
- Fully Connected Layers
완전히 연결 되었다라는 뜻으로, 한층의 모든 뉴런이 다음층이 모든 뉴런과 연결된 상태로 2차원의 배열 형태 이미지를 1차원의 평탄화 작업을 통해 이미지를 분류하는데 사용되는 계층입니다.
- 2차원 배열 형태의 이미지를 1차원 배열로 평탄화
- 활성화 함수(Relu, Leaky Relu, Tanh,등)뉴런을 활성화
- 분류기(Softmax) 함수로 분류
[출처] [딥러닝 레이어] FC(Fully Connected Layers)이란?|작성자 인텔리즈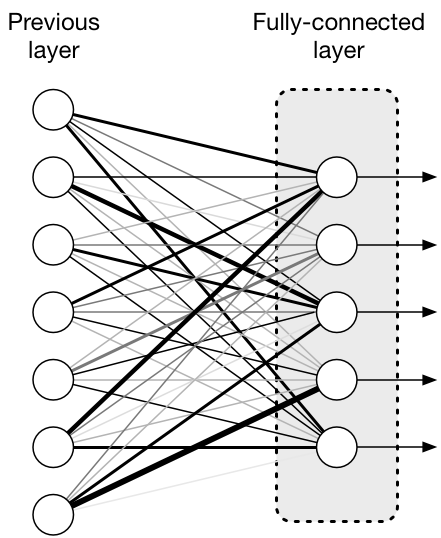
AutoEncoder vs. PCA(주성분 분석)
둘 다 feature extraction을 위한 기법들.
- 데이터가 선형으로 분리되지 않은 경우 PCA를 이용해 데이터의 차원을 낮추게 되는 경우 원래 데이터가 갖고 있는 특성을 잃어버릴 수 있다. 이 때는 비선형 kernel PCA/ Auto-encoder를 사용해야 한다.
Deterministic vs. Stochastic
- deterministic: 하나만 고르는! 결과가 하나인
- Stochastic: 확률에 따른 분포를 보인다
Self-Supervised vs. Semi-Supervised vs. Unsupervised Learning
- Unsupervised Learning: 데이터가 없는 상황에서 어떻게 처리할 수 있는가
- Unsupervised Learning에 Self-Supervised, Semi-Supervised 등이 존재한다.
- Self-Supervised Learning: (X,y) 데이터 셋이 아예 없는, X만이 주어진 상태에서 판단
- Semi-Supervised Learning: (X,y) 데이터 셋과 X 데이터셋이 동시에 존재한다.
Latent Vector / Latent Space / Latent Variable / Latent Feature
모델이 데이터를 바라보는 표현(latent feature)을 space/variable/vector에 담은 것
- Latent Space
- Latent Variable
- Latent Vector
- Latent Feacture
Bottleneck
병목 현상?
- ResNet에서의 Bottleneck Architecture
- AutoEncoder에서의 Bottleneck
Learning Rate Scheduler
처음부터 끝까지 같은 learning rate를 사용하는 것이 아닌, 학습하는 과정에서 learning rate를 조정하는 방법. 일반적으로 optimizer를 정의한 후에 scheduler를 정의한다. 이후에 optimizer.step(), scheduler.step()으로 조정이 가능하다.
Sigmoid vs. ReLU vs. Softmax
- Activation function
- Sigmoid function: 입력값의 절댓값이 커질수록 기울기가 0에 가까워져 back-propagation 진행시 Gradient vanishing의 결론에 이른다.
- ReLU function: Gradinet vanishing 이 일어나지 않고 역전파에서 학습이 빠르다.
- Softmax function: 출력노드의 활성화 함수로 많이 사용된다. 이 함수에서 각 출력값은 0~1을 가지게 된다.
- Sigmoid function: 입력값의 절댓값이 커질수록 기울기가 0에 가까워져 back-propagation 진행시 Gradient vanishing의 결론에 이른다.
Continual learning vs. Active learning vs. Multi-task learning vs. Meta-learning vs. Few/One/Zero-shot learning
- Active learning: (아닐 수도 있음: 하나의 task에 대해서 학습하는 것 같음). 기계가 라벨링이 필요한 데이터 중 자동적으로, 그리고 점진적으로 가장 정보량이 많은 데이터를 선택하는 것
- Few/One/Zero shot learning: Transfer Learning과 Meta-Learning은 둘 다 Few-shot Learning을 위해 제안된 알고리즘이다. 적은 데이터만을 가지고 좋은 성능을 뽑아내기 위한 방법론들을 다루는 연구 분야.
- Fine-tune vs. Few-shot learning
- Fine-tune: When you already have a model trained to perform the task you want but on a different dataset, you initialise using the pre-trained weights and train it on target (usually smaller) dataset (usually with a smaller learning rate). - Dataset shift에 따른 학습 처리
- Few-shot: When you want to train a model on any task using very few samples. e.g., you have a model trained on a differen the related task and you (optionally) modify it and train for target task using small number of examples.
- Task 중심
- Continual learning: 하나의 모델을 조금씩 업그레이드 시키면서, 여러 Task를 처리할 수 있도록 만드는 방법
- Meta-learning: 다른 Task를 위해 학습된 AI 모델을 이용해서, 적은 Dataset을 가지는 다른 Task도 잘 수행할 수 있도록 학습시키는 방식
- Multi-task learning: 서로 연관 있는 과제들을 동시에 학습함으로써 모든 과제 수행의 성능을 전반적으로 향상시키려는 학습 패러다임
'AI, Deep Learning Basics > Basic' 카테고리의 다른 글
| [Basic] Activation Function/Loss Function/Evaluation metric (0) | 2022.02.12 |
|---|---|
| [기초] 딥러닝 성능 높이기: 층을 깊게 하는 것에 대하여 (0) | 2022.01.15 |
| (작성중) [기초] 3. Overfitting/Underfitting 및 Regularization일반화/일반화 기법 (0) | 2022.01.09 |
| [Probability] MLE를 통한 MAP 추론: Posterior/Prior/Likelihood -Bayes rule/Bayesian Equation (0) | 2022.01.08 |
| [기초] 2. Optimization최적화기법/최적화: 매개변수 초기화 및 갱신 (0) | 2022.01.08 |
- Self-Supervised Learning
- Pre-training vs Fine-tuning
- Domain
- Model Compression
- Bounding Box
- Reinforcement Learning
- Search Algorithm
- Spatial Pyramid Pooling
- FCN(Fully Convolutional Networks)
- 추가. FPN vs. FCN vs. FC layer
- AutoEncoder vs. PCA(주성분 분석)
- Deterministic vs. Stochastic
- Self-Supervised vs. Semi-Supervised vs. Unsupervised Learning
- Latent Vector / Latent Space / Latent Variable / Latent Feature
- Bottleneck
- Learning Rate Scheduler
- Sigmoid vs. ReLU vs. Softmax
- Continual learning vs. Active learning vs. Multi-task learning vs. Meta-learning vs. Few/One/Zero-shot learning