![[Deep Learning]하나의 훈련 데이터로 본 딥러닝 기반 신경망 알고리즘 적용](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FYO5ac%2FbtrlEUevJLw%2FG52kML3KCXwVN5yJSzwNv1%2Fimg.jpg)
*이 글은 Coursera: Neural Networks and Deep Learning(Andrew Ng)과 데이터 과학을 위한 통계(피터 브루스, 앤드루 브루스 지음) 을 참조하여 작성되었습니다.
Deep Learning 시 이용되는 Neural Network 알고리즘을 이용하여
하나의 훈련데이터를 이용하여 Hidden Layer에 적용하는 일련의 목차를 설명드리고자 합니다!
입력값X와 결과값Y를 입력하고 기계에게 알고리즘을 직접 적용하여 기계가 적용된 알고리즘을 이용하는 머신러닝의 부분과는 다르게, 딥러닝은 입력값X와 결과값Y를 입력하면 기계는 이러한 X,Y 값을 학습하여(우리가 적용하지 않고) 입력값을 제시시 기계가 알아낸 학습값을 나타냅니다.
먼저 일반적인 파라미터(Parameter) 개념 및 기본 개념들을 알아보도록 하겠습니다!
Input입력값 X, 그 값에 따른 Y(입력값에 연결되는 값) :
우리가 먼저 가지고 있고, 기계에게 학습해야 할 전체! 훈련데이터입니다. 행렬들로 이루어져 있습니다.
입력값 X를 (n,m)의 형태로 나타낼 수 있을 때, 이 때 m개의 훈련데이터로 이루어졌다고 보시면 됩니다.
(하나의 열은 하나의 훈련 데이터를 말합니다. 이번 시간에는 하나의 훈련 데이터로 학습하는 일련의 과정을 보시게 될 겁니다.)

X,Y은 행렬이므로 숫자로 나타내지며, 이진법의 뜻을 따르거나(0과 1) 색의 조합을 따르는 등의 방법으로 표현됩니다.
예를 들어 입력값 x를 통해 고양이가 맞는지 확인하기 위하여 이진법을 따르면 고양이가 맞다면 y= 1, 맞지 않다면y= 0으로 표현하는 방법이 있습니다.
기댓값 yhat

: 이 값은 특정한 x 값에서 y가 그 특정한 값과 맞는지를 나타내는 확률값입니다.
문제들에 따라 다르겠지만 예시를 들면 =P(y=1|x)라고 표현할 수 있습니다.
Parameters변수 W,b,Z,A : 우리가 사용하는 신경망 알고리즘은 선형 모델의 모습을 띄고 있는데 이때에 필요한 변수들입니다.
이어서 간단한 기본 개념들을 설명드리겠습니다.
Activation Function활성 함수 :
여러가지 변수와 x값을 이용하여 하나의 값으로 나타내었을 때 이 수가 여러가지 범위의 값으로 표현될 것입니다. 이때 활성함수를 이용하여 산발적으로 퍼져있는 값들을 확률의 범위인 0과 1 사이의 값으로 나타낼 때 쓰이게 되는 함수들입니다. 함수들이 여러가지라서 설명드리기 힘들지만, 대표적인 예시로는 Relu, Sigmoid, tanh(x), Leaky Relu 함수 등이 있어서 나름대로의 장단점이 있어서 상황에 따라서 골라 쓰시면 됩니다.(함수 관련한 정보는 나중에 포스팅 할 예정입니다.) 이번 시간에는 이중에서도 아주 대표적으로 쓰이는 Sigmoid시그모이드 함수를 이용합니다.
이 함수 관련해서는 밑에 나와있어서 참조하시면 도움이 되실 겁니다!
Backward Propagation역전파 :
W,b 등의 변수들을 이용하여 예측을 하였을 때 맞지 않는 경우가 생기는 건 흔한 일입니다. 우리는 이 변수 값들을 조정을 하는 일이 필수겠지요. 그러기 위해서 결과값에서부터 입력값으로 가면서 변수들을 조정하는 일을 하는데요, 이 방향을 일컬어 역전파라고 하여 (순전파의 반대로) 작용하여 변수들을 조정하는 일들을 말합니다.
Forward Propagation순전파 :
입력값에서부터 결과값으로 가면서 변수들을 조정하는 일들을 말합니다.
그럼 시작하겠습니다.
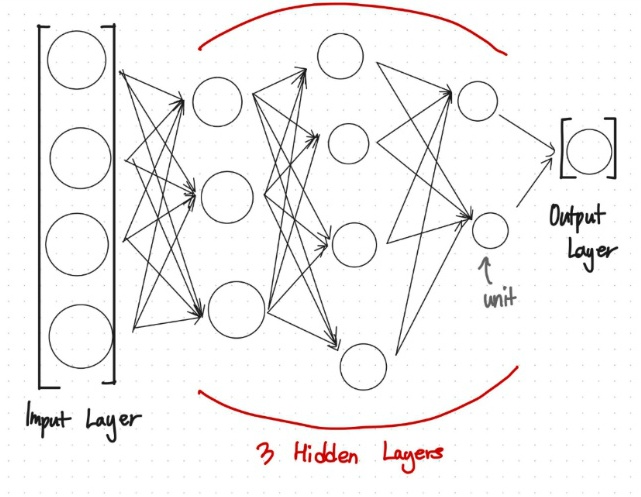
먼저 신경망 함수가 어떻게 작용되는지 그림과 더불어 설명드리고자 합니다.
이 그림은 여러분들이 많이 보셨을 그림입니다.

여기서 화살표들은 전 동그라미에서 어떠한 과정을 거쳐서 후 동그라미로 갔는데요, 이러한 동그라미들은 이러한 과정을 거친 후에 나타나는 값들이라고 보면 됩니다.
그렇게 본다면 화살표가 없는 맨 첫번째 값은 Input 입력값 즉, X 값을 나타내고, 이러한 일렬의 x 값들이 모였을 때 Input Layer 라고 부릅니다.
화살표가 제일 많이 적용된 가장 뒤의 값은 이러한 학습과정을 거쳐서 나타낸 결괏값, yhat
입니다.(출력값 Y 아닙니다! 학습을 거친 값이므로
으로 보아야 합니다!!) 이 때 나타나는 값을 Output Layer에 저장되게 됩니다.
사이에 나타나는 Layer 들은 작업이 되는 레이어들로 Input Layer와 Output Layer사이에서 보이지 않는 Layer라고 하여 Hidden Layer라고 불립니다. 안에 있는 작은 동그라미 하나하나는 Unit이라고 불립니다.
우리의 목표는 훈련데이터들을 통하여 Hidden Layer 의 체계를 완성한 후에, 가지고 있는 테스트 데이터를 완성된 Hidden Layer에 적용하여 예측하는 일입니다.
그러므로 Hidden Layer의 Unit들 하나하나에 포함되어 있는 파라미터 W,b들을 훈련 데이터에 맞게 조정하는 일은 필수적입니다.
이러한 Layer 들은 X,Y 값들 자체가 행렬값으로 계산되므로 Layer도 행렬값으로 표현 됩니다.
Input Layer X, Output Layer Y, Hidden Layer

(k번째 Hidden Layer의 행렬 A)으로 나타냅니다.
말한 것을 정리해보면 이렇게 보시면 됩니다.
순전파 함수 적용하기
입력값X에 있는 임의의 값

를 Hidden Layer Unit에 있는 값 a로 나타나는 것이 저희의 목표입니다!
앞서서 말씀드린대로 신경망 알고리즘은 선형 모델의 모습을 띄고 있습니다.
이 때 선형 회귀 모델의 예측 공식은 다음과 같습니다.

여기서 나타나는 [0]~[p]값은 x 특성으로 p개이므로 특성의 개수를 이야기합니다.
이번 시간에는 특성 하나만 다루는 것이기 때문에 x하나로 단정지어 설명해보도록 하겠습니다.

y = ax+b의 식을 우리가 가진 변수로 사용하여 z=wx+b로 나타내고자 합니다.
처음부터 w,b를 예측할 수 있는 상황을 만들 수 없으므로, w는 0이 아닌 임의의 랜덤 값으로 배정받고, b도 랜덤값으로 배정받습니다.
이게 가능한가 의아해 하시는 분들이 있으시겠지만 걱정하지 마세요!! 역전파 함수로 어차피 다들 y 값에 맞춰서 바뀌어질 애들입니다.
이때 z값은 임의의 w,b와 훈련데이터 x로 나타내진 값이기 때문에 여기저기 흩어져있는 값일 것입니다.
이를 모으기 위하여 앞서 말씀드린 대로 Activation Function활성 함수의 쓰임(값들을 0과 1로 사이의 값으로 수렴하기 위하여)이 필요합니다.
여기서는 Sigmoid시그모이드 함수를 이용하겠습니다.



이를 통해서 우리가 가진 x 값은 하나의 Hidden Layer를 거쳐서 0과 1 사이에 확률값 a로 나타나게 되었습니다.
하나의 데이터 값 x가 어떻게 Hidden Layer로 계산되어 들어가는지 일련의 계산과정을 보셨습니다.
다음포스팅에는
하나의 데이터 값이 아닌, m개의 training data set이 Hidden Layers에서 어떻게 계산되는지와 함께,
이번에 보여드리지 못한 역전파 함수도 같이 보여드리겠습니다!!
끝까지 봐주셔서 감사드리고, 오늘도 좋은 하루 보내세요!!
*궁금한 점이나 조언은 댓글로 남겨주세요!!